If you’ve ever used Google Translate, ChatGPT, or even typed a message and had your phone autocomplete it smartly, you’ve experienced the real-world impact of a landmark 2017 research paper titled Attention Is All You Need. Published by researchers at Google Brain and Google Research, this paper didn’t just improve existing AI, it fundamentally rewired how machines understand language. Today, nearly every major AI language system in the world traces its roots back to this single publication.

So what exactly did Attention Is All You Need propose? Why did it matter so much? And how does it actually work? Let’s break it down in a easy language.
Table of Contents
What Problem Was “Attention Is All You Need” Trying to Solve?
Before 2017, the dominant approach to teaching machines to process language was through Recurrent Neural Networks, or RNNs – particularly a variant called LSTMs (Long Short-Term Memory networks). Imagine reading a sentence one word at a time, and having to remember everything you’ve read so far. That’s essentially what RNNs did.
The problem? They were slow and had a bad memory. When sentences got long, RNNs struggled to retain information from the beginning by the time they reached the end. Worse, because they processed words sequentially (one at a time), they couldn’t take advantage of modern hardware that excels at doing many things at once in parallel.
This is the exact challenge that Attention Is All You Need set out to solve. The authors – Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin – asked a bold question: What if we threw out the sequential processing entirely and relied purely on attention?
What Is “Attention” in Machine Learning?
Before diving deeper into Attention Is All You Need, it helps to understand what “attention” means in the context of AI.
Think about how you read a sentence: “The trophy didn’t fit in the bag because it was too big.”
When you try to figure out what “it” refers to, your brain naturally focuses more on “trophy” than on “bag.” You’re paying attention to the most relevant part of the sentence.

In machine learning, an attention mechanism works similarly. It allows the model to weigh the importance of each word in relation to every other word in the sentence — all at the same time. Instead of trudging through words one by one, the model can instantly assess how relevant any word is to any other word.
The paper Attention Is All You Need took this concept and ran with it – building an entire architecture, called the Transformer, based solely on attention. No recurrence. No convolutions. Just attention, done cleverly.
How the Transformer Architecture Works
The core architecture introduced in Attention Is All You Need is called the Transformer, and it has two main components: an encoder and a decoder.
The Encoder reads the input (say, a sentence in English) and converts it into a rich internal representation – a kind of meaning-map of the sentence. It’s made up of 6 identical layers, each containing two parts: a multi-head self-attention mechanism, and a feed-forward neural network.
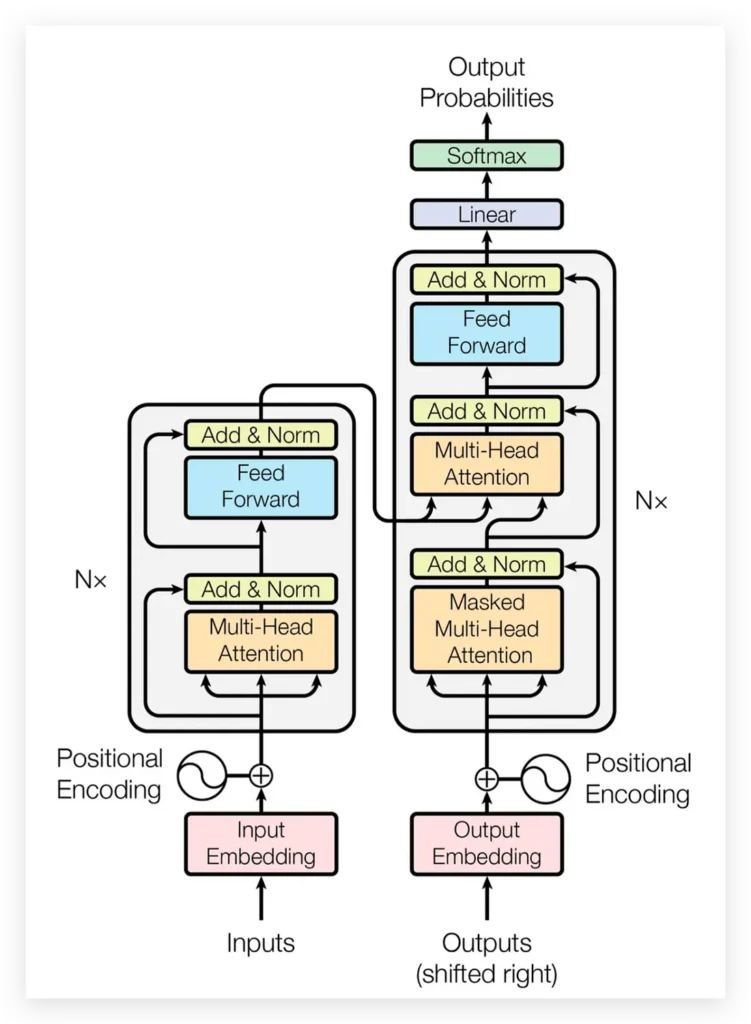
The Decoder takes that internal representation and generates the output (say, the same sentence in German), word by word. It also has 6 layers, but with an added attention layer that lets it look back at the encoder’s output while generating each new word.
Both components use something called residual connections and layer normalization, which are techniques that help the model train more stably — think of them as guardrails that keep learning on track.
The Secret Sauce: Scaled Dot-Product Attention and Multi-Head Attention
Two specific mechanisms make Attention Is All You Need so powerful.
Scaled Dot-Product Attention
This is the mathematical core of the Transformer. For each word (or “token”), the model creates three vectors: a Query (what am I looking for?), a Key (what do I represent?), and a Value (what information do I carry?).
The model computes attention scores by comparing queries against all keys, then uses these scores to create a weighted combination of values. The “scaled” part refers to dividing by the square root of the key dimension — a small but important trick to prevent numerical instability during training.
The formula is elegantly simple:
Attention(Q, K, V) = softmax(QKᵀ / √dk) × V
Multi-Head Attention
Rather than computing attention just once, the Transformer does it eight times simultaneously, each time focusing on different aspects of the relationships between words. It’s like having eight proofreaders, each reading the sentence with a different lens — one for grammar, one for context, one for tone, and so on.
The results are then combined (concatenated) and projected into the final output. This “multi-head” approach is one of the key reasons why Attention Is All You Need outperformed previous models so dramatically.
Also Read Kerala High Court bans AI in Judicial Functions analysis by Nikita Soni
Why “Attention Is All You Need” Outperforms Traditional Models
The paper makes a compelling case for why self-attention is superior to recurrence and convolution across three dimensions:
1. Computational Complexity: Self-attention processes all positions simultaneously in O(1) sequential operations, versus O(n) for recurrent layers. In plain English: the Transformer can process the whole sentence at once, while RNNs have to go word-by-word.
2. Long-Range Dependencies: In an RNN, information from the first word must travel through every subsequent step to reach the last word. In the Transformer, any two words can directly “talk” to each other regardless of how far apart they are. This makes it far better at understanding complex, long sentences.
3. Parallelization: Because there’s no sequential processing, the Transformer can be trained on modern multi-GPU hardware much more efficiently. The paper reported that their big model trained in just 3.5 days on 8 GPUs — a fraction of the time competing models required.
The Results: A New State of the Art
The experimental results presented in Attention Is All You Need were striking. On the WMT 2014 English-to-German translation benchmark, the Transformer (big model) achieved a BLEU score of 28.4 — more than 2 points better than every existing model, including ensembles of multiple models. A BLEU score is a standard metric for translation quality; higher is better.
On English-to-French translation, the big Transformer achieved 41.0 BLEU, setting a new single-model record while using less than one-quarter the computational cost of the previous best model.
The base model alone already outperformed all previously published models — and it trained in just 12 hours.
Positional Encoding: Teaching the Model About Order
One of the clever details in Attention Is All You Need is how the Transformer handles word order. Since attention looks at all words simultaneously, it has no built-in sense of which word comes first.
The solution? Positional Encoding — a set of mathematical signals (using sine and cosine functions of different frequencies) that are added to each word’s representation before it enters the model. These signals give each position a unique “fingerprint,” allowing the model to reason about sequence order without any recurrent processing.
The researchers also tested learned positional embeddings and found nearly identical results — suggesting the sinusoidal approach works just as well and has the advantage of potentially generalizing to longer sequences than seen during training.
The Legacy: How “Attention Is All You Need” Changed Everything
It’s hard to overstate the impact of Attention Is All You Need. Within just a few years, it gave birth to:
- BERT (Google, 2018) — a Transformer-based model that revolutionized search engines
- GPT series (OpenAI, 2018–present) — the family of models behind ChatGPT
- T5, PaLM, LLaMA, Gemini — virtually every major language model today
- Transformers for images (Vision Transformer / ViT), audio (Whisper), code (GitHub Copilot), and more
The architecture proposed in Attention Is All You Need didn’t just improve NLP — it spread to computer vision, audio processing, protein structure prediction (AlphaFold), and beyond. It is, without exaggeration, the foundation of modern AI.
Frequently Asked Questions (FAQ)
Q1: What is “Attention Is All You Need” about in simple terms? It’s a 2017 research paper that introduced the Transformer model — an AI architecture that uses “attention” to understand relationships between words in a sentence, replacing older, slower methods. It powers tools like ChatGPT and Google Translate.
Q2: Who wrote “Attention Is All You Need”? The paper was written by eight researchers: Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin — most of whom were at Google at the time.
Q3: Why is attention better than recurrent neural networks? Recurrent networks process words one at a time and struggle with long-range dependencies. Attention allows the model to consider all words simultaneously, making it faster, more parallelizable, and better at capturing relationships between distant words.
Q4: What is a BLEU score? BLEU (Bilingual Evaluation Understudy) is a metric used to measure the quality of machine-translated text. Higher scores indicate translations that are closer to human-produced references.
Q5: Is the Transformer model still used today? Absolutely. The Transformer is the backbone of nearly every state-of-the-art AI language model today, including GPT-4, Gemini, Claude, and BERT. It has also been extended beyond text to images, audio, and scientific applications.
Q6: Can I read “Attention Is All You Need” myself? Yes! The original paper was published at NeurIPS 2017 and is freely available on arXiv (arXiv:1706.03762). The code was open-sourced via Google’s tensor2tensor library on GitHub.
Q7: What does “multi-head attention” mean? It means the model runs the attention mechanism multiple times in parallel (8 times in the original paper), each “head” learning to focus on different types of relationships between words. The results are then combined.
Q8: What is positional encoding in the Transformer? Since the Transformer processes all words at once, it needs a way to know word order. Positional encoding adds a unique mathematical signal to each word’s input representation based on its position in the sequence.
About the Authors
Attention Is All You Need was authored by eight researchers, primarily from Google Brain and Google Research. Ashish Vaswani and Illia Polosukhin designed and implemented the first Transformer models. Noam Shazeer contributed key innovations including scaled dot-product attention and multi-head attention. Jakob Uszkoreit proposed replacing RNNs with self-attention, catalyzing the entire effort.
Niki Parmar and Llion Jones were responsible for model variants and the initial codebase. Łukasz Kaiser and Aidan N. Gomez (then at the University of Toronto) built the tensor2tensor framework that made large-scale experiments possible. All eight are listed as equal contributors – a fitting tribute to a genuinely collaborative breakthrough that reshaped the trajectory of artificial intelligence and continues to underpin virtually all large language models deployed at scale today.
Found this helpful? Share it with someone learning about AI. The revolution in machine intelligence starts with understanding the ideas behind it.